
How Claude Code became the primary interface for planning, building, and shipping a major platform feature. It synthesized scattered project context, produced working prototypes in days instead of sprints, and collapsed the overhead of working across Jira, GitHub, AWS, and a dozen other tools. The AI's output is mostly wrong, and that's the point: fast correction cycles compound into knowledge that makes every future session better. By Bryan Fauble.
authors |
Bryan Fauble |
|---|
Interfacing with the world today is increasingly complex. Every tool we touch requires its own mental model. Jira has its JQL. GitHub has its review flow. AWS requires multiple consoles open simultaneously to debug a single request. Confluence pages are scattered across spaces and may or may not reflect current reality.
My work at Sage Bionetworks, creating and maintaining open source software, amplifies this. Code and people are spread across dozens of repositories, processes, Confluence documents, and knowledge that isn't written down anywhere. The Synapse platform backend alone spans 800,000+ lines of Java/Spring, backed by MySQL and a decade of accumulated conventions that exist for good reasons but live in engineers' heads.
For the past several weeks I've used Claude Code as the primary interface through which I do my work. What emerged wasn't just a faster way to write code. It was a repeatable workflow for delivering an entire initiative, from onboarding through production. Portal Search is where I'm proving it out.
The Workflow
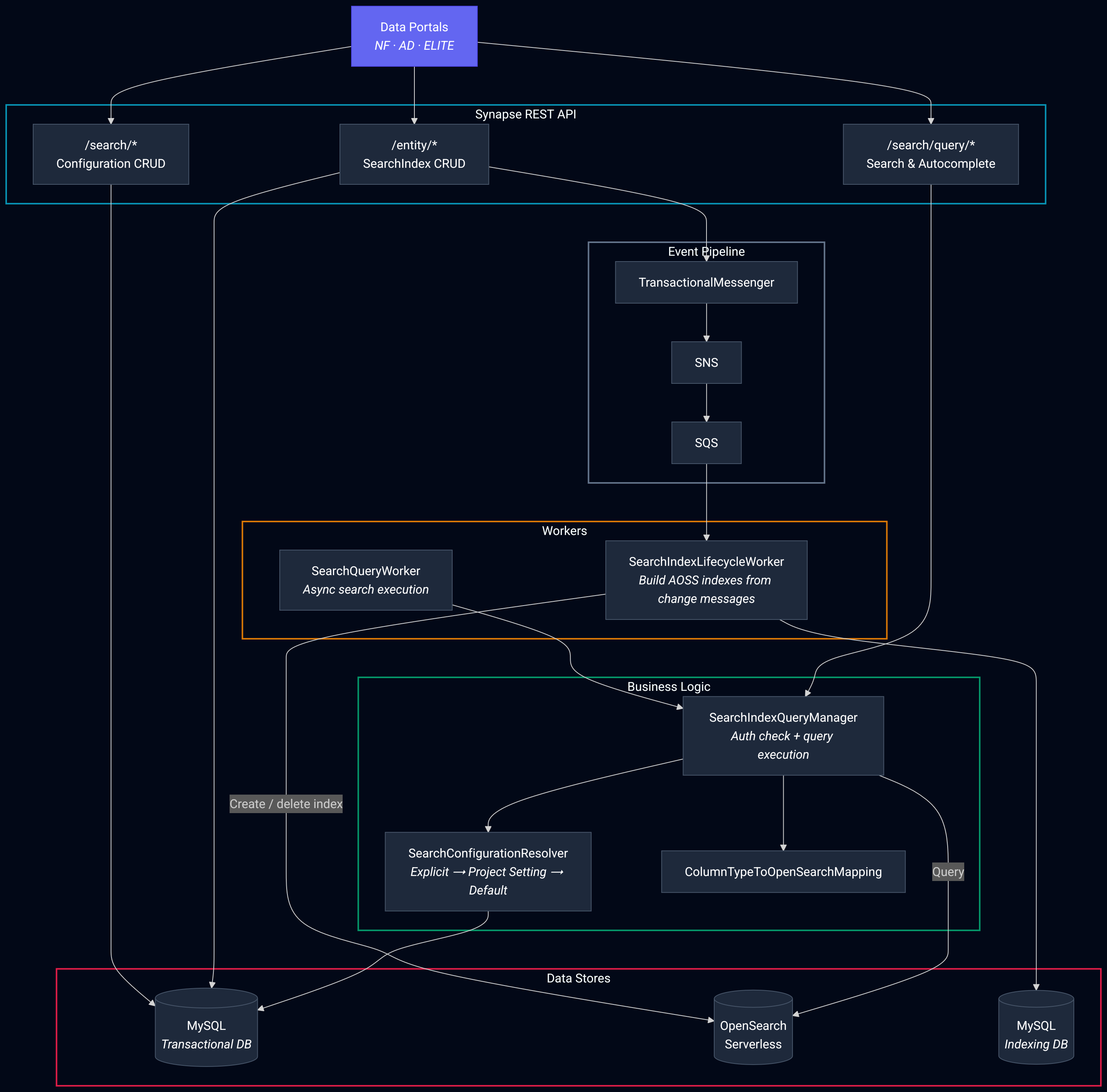
Portal Search is replacing Synapse's MySQL Full Text Search with AWS OpenSearch Serverless across our data portals. The initiative is ongoing, but the workflow that emerged from it generalizes beyond any single project. Here's the pattern I've landed on.
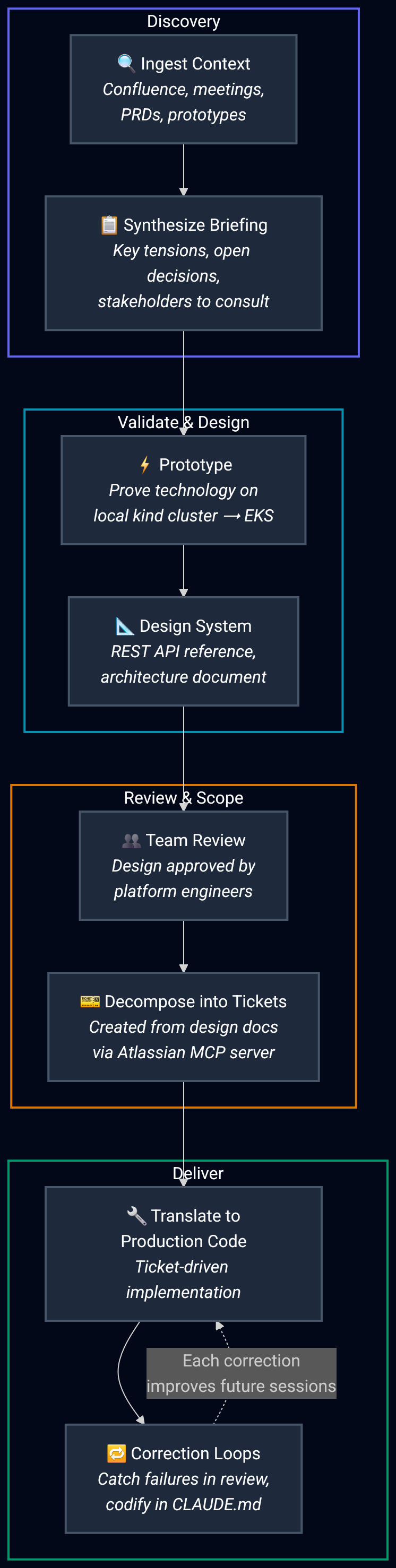
Each phase uses Claude differently, but the throughline is the same: feed it context from multiple systems, let it synthesize, correct the output, and encode what you learned so the next cycle starts from a higher baseline.
Ingest and synthesize
When I joined Portal Search, dozens of meetings, conversations, product requirement documents, and stakeholder decisions had already happened. I tracked down everything that had been written down (Confluence pages, meeting notes, prototype videos, technical proposals) and passed it all into Claude to synthesize.
The result was a structured briefing that surfaced key tensions: serverless versus managed OpenSearch clusters, single-table versus catalog-based index architecture, which portals to target first, and which scope was realistic for Q1. It identified the people I needed to talk to and the decisions that hadn't been resolved yet. What normally takes a week of reading and hallway conversations was compressed into a directed starting point.
Learning: When an organization has more projects than people, the speed at which someone becomes effective on a new initiative directly impacts what the team can deliver. Feeding Claude the full written record of a project and asking it to synthesize a briefing is now the first step of every new initiative.
Prototype to validate
Before committing to a formal design, I needed to prove that OpenSearch could actually solve the problem. The briefing surfaced the core questions, but the only way to answer them was to put real data into a real index and see how it behaved. Could our portal datasets be indexed effectively? Was this a matter of configuring OpenSearch correctly for our use case, or was there a fundamental mismatch?
Using GitHub Copilot with Claude Opus, I built a working prototype: a web UI backed by a real OpenSearch index, running on a local Kubernetes kind cluster with k9s for real-time pod monitoring and debugging. Once it worked locally I deployed the same manifests to AWS Elastic Kubernetes Service and opened access to Sage VPN users.
The prototype answered the key questions quickly. OpenSearch handled our data well. The challenges were configuration: analyzer tuning, field mapping strategies, and how to structure the index for the query patterns our portals actually use. That validation shaped everything that came after.
Learning: A kind cluster running locally alongside k9s collapses the prototype-to-deployment gap. You build against real Kubernetes infrastructure, debug interactively, and deploy to EKS with minimal changes. Claude moves fluently between Dockerfiles, Helm charts, Kubernetes manifests, OpenSearch configuration, and application code in a single session. The result isn't a throwaway mockup; it's a directly deployable artifact.
Design informed by prototype
With the technology validated, I could design the production system with confidence rather than speculation. The prototype had already exposed the real constraints: how OpenSearch handles our column types, what analyzer configurations produce useful search results, and where the integration points with Synapse's existing entity lifecycle need to live.
From there I produced two documents: a REST API reference defining the complete API surface, and an architecture document covering the SearchIndex entity, its lifecycle, OpenSearch integration points, and the authorization model. I used Claude and Gemini to stress-test the design, surfacing gaps, logical inconsistencies, and error recovery scenarios that drove key architectural pivots before any production code was written.
The architecture was shaped by accumulated engineering knowledge: previous engineers' explorations, product requirements, platform engineer feedback, what I learned from the prototype, and my own understanding. Claude helped synthesize those into structured deliverables.
Learning: Prototyping before designing inverts the usual risk. Instead of designing around assumptions about how a technology behaves, you design around observed behavior. The prototype de-risks the design, and the design becomes a plan for translating something that already works into something production-ready.
Review, scope, and decompose
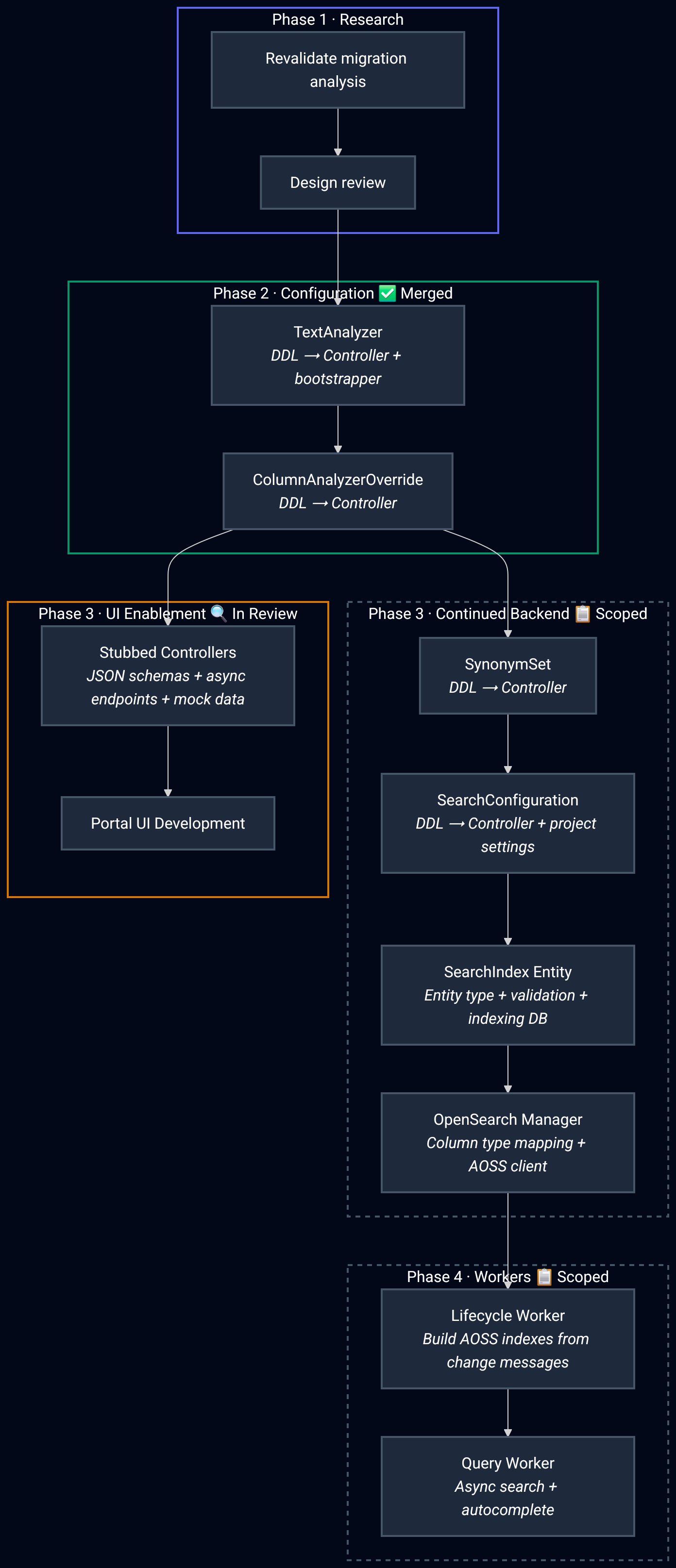
The design documents were reviewed and approved by other members of the platform engineering team. None of the artifacts produced up to this point are perfect. The design has gaps. The architecture document makes assumptions that will prove wrong. That's expected. What matters is that the review process catches the most consequential issues before they propagate downstream, and that the remaining imperfections surface during code review rather than in production.
From the approved design, I decomposed the work into discrete Jira tickets, each one traceable to a specific section of the REST API reference or architecture document. The entire epic (ticket creation, acceptance criteria, dependency mapping, and status tracking) is managed through the Atlassian MCP server, which means project management happens from the same Claude Code interface used for development. Design documents become actionable tickets. Tickets drive code. Code goes through review. At every stage, imperfect artifacts get refined through human scrutiny.
So far, the TextAnalyzer and ColumnAnalyzerOverride configuration resources have been merged. Stubbed controllers that will unblock portal UI development are proposed and in review. The remaining work (SearchConfiguration, SearchIndex entity, OpenSearch Manager, lifecycle workers, and query workers) is carefully scoped into individual Jira tickets under the epic, each with clear acceptance criteria and dependencies mapped.
Translate and correct
Each ticket drives a unit of production code. Using Claude Code with the Opus 4.6 model and its 1 million token context window, I direct it to read the Synapse-Repository-Services codebase, the prototype, and the specific ticket's acceptance criteria simultaneously, then produce a Synapse-native implementation in Java adhering to the lifecycle patterns, naming conventions, and under-documented behaviors the project has accumulated over a decade.
The first pass compiled and ran after a few sessions. Getting it correct within the project's context took real time. Claude Code has no built-in sense of correctness. The failure rate in early sessions ran 60–80%: hallucinated APIs, missed imports, wrong class hierarchies, and in one case a security vulnerability where an authorization check validated caller-controlled input instead of stored state.
The implementation so far spans 6 PRs in Synapse-Repository-Services alone, with additional PRs for infrastructure. The pace (69 commits and 252 files changed in two weeks) reflects what happens when corrections are cheap to make. As the remaining tickets move through development, each one follows the same translate-correct-review cycle. This will give our data portals a significantly more effective search tool, and the implementation extends beyond portals to any dataset where OpenSearch would outperform existing query mechanisms.
The Same Workflow, Simultaneously
Portal Search isn't the only initiative running. The same workflow is powering work on the Synapse MCP server (OAuth, AWS ECS deployment, DNS migration), the Curator MVP automation project, and cross-system debugging across all of them, within the same quarter. The pattern scales because the cognitive overhead lives in Claude's context window, not in my head.
Consider the number of technologies a project like Portal Search touches: Java, Spring, MySQL, AWS OpenSearch Serverless, CloudFormation, Docker, Kubernetes, Helm, SNS, SQS, OAuth, WAF rules, Redis, GitHub Actions, and the Synapse-specific conventions layered on top. Each one has its own configuration language, its own debugging workflow, its own documentation. Traditionally, moving between any two of these requires rebuilding mental state from scratch. Claude holds all of them simultaneously.
When a 403 error blocked our MCP server's OAuth flow, instead of bouncing between application logs, the CloudFormation console, and the WAF console, I pointed Claude Code at the logs and our CloudFormation repo simultaneously. It cross-referenced both and identified the specific WAF rule triggering on OAuth's standard redirect_uri parameter. When Redis session storage started throwing CROSSSLOT errors after deploying to ElastiCache Serverless, same pattern: one session, multiple systems, answer in minutes.
Learning: The value isn't that Claude knows any one technology better than you do. It's that it holds the full picture at once, eliminating the tax of rebuilding mental state every time you move between tools.
Skills compound this further. One skill performs code reviews by fetching the PR from GitHub, auto-detecting the Jira ticket, pulling requirements, and generating a review that cross-references code against acceptance criteria. Another triages Gmail by parsing emails for Jira and GitHub references, fetching context from both, and executing actions across all systems from a single interface. Each replaces a workflow that previously required holding state across 3 to 5 disconnected tools.
Most of It Is Wrong, And That's the Point
Over the course of this work (104 commits across 5 repositories, 17 pull requests) the majority of Claude's output needed human correction. Some corrections were minor. Others were architectural. One was a security vulnerability I caught during review.
The correction rate is not the interesting number. The interesting number is how fast you can close the loop. A mistake caught and fixed in the same session is fundamentally different from one caught in code review days later or in production weeks later. When the cost of correction drops, you can afford to iterate aggressively.
Every correction is an opportunity to make the tool better. Claude Code supports persistent configuration through CLAUDE.md files that it reads at the start of every session. When Claude gets something wrong, the convention gets added to the CLAUDE.md file for that module. The result is a network of these files distributed throughout the project, each encoding the conventions and failure modes specific to that layer.
Learning: Multi-step workflows can be captured as skill files: how to stand up an async job pipeline, how to implement a feature across every layer, how to selectively commit changes for one ticket when your working tree contains work for several. These encode the things principal engineers carry in their heads.
This means the tool gets better over time in a way that benefits the whole team. A new engineer onboarding to this codebase doesn't just get documentation; they get a set of executable conventions that guide Claude toward correct output from the start. The correction rate from the early sessions is the worst it will be.
What This Means
AI in the hands of someone without a grasp of the fundamentals is dangerous.
The failure rate on AI-generated suggestions is too high to skip careful scrutiny, especially when that code creates the path for the outside world to access public and private data. It is our collective responsibility to secure and harden every layer of the software stack. The tool scales expertise. It does not substitute for it.
What changed is where I spend my time. Before: switching between tools, reconstructing state, remembering how each system works. Now: steering Claude through the work while it holds the cross-system context for me. The cognitive load moved from "how does this tool work" to "is this output correct."
Synapse manages 3.9+ petabytes of data with over 10 petabytes of data egress in 2025 alone. In an organization where technical work spans multiple teams and capacity is always finite, reducing that overhead matters. Not because the AI does the work, but because it removes the friction that fragments attention across a dozen disconnected tools. One interface. Human steering. Compounding knowledge.
This work was also supported in part by API credits from Anthropic’s AI for Science program.
Terms Glossary
AI Tools
Claude Code — Anthropic's command-line agentic coding tool. Used in the article as the primary development interface. → code.claude.com/docs
Claude Opus 4.6 — The most advanced model in the Claude 4.6 family, featuring a 1-million-token context window. Referenced as the model powering the implementation sessions.
GitHub Copilot — AI pair-programming assistant integrated into code editors. Used in the article for early prototyping with Claude Opus. → github.com/features/copilot
Gemini — Google's family of AI models. Used alongside Claude to stress-test the system design. → deepmind.google/technologies/gemini
CLAUDE.md — A persistent configuration file read by Claude Code at the start of every session. Used to encode project conventions, naming rules, and lessons from past corrections so that future sessions start from a higher baseline.
Skills (Claude Code) — Reusable workflow definitions that capture multi-step processes (e.g., code review, email triage) as executable routines within Claude Code.
Project Management & Documentation
Jira — Atlassian's issue-tracking and project-management tool. Used to decompose designs into tickets with acceptance criteria. → atlassian.com/software/jira
JQL (Jira Query Language) — Jira's structured query language for filtering and searching issues. → JQL reference
Confluence — Atlassian's wiki and documentation platform. Mentioned as a source of scattered project context. → atlassian.com/software/confluence
Atlassian MCP Server — A Model Context Protocol server that lets Claude Code interact with Jira and Confluence directly, enabling project management from the development interface. → MCP docs
Epic — In Jira, a large body of work broken down into smaller tickets (stories/tasks). Portal Search is tracked as an epic.
Languages & Frameworks
Java — The primary language of the Synapse backend. → dev.java
Spring (Spring Framework) — Java application framework underpinning Synapse Repository Services. → spring.io
MySQL — Relational database used by Synapse, including its Full Text Search feature that Portal Search is replacing. → mysql.com
Search Technology
AWS OpenSearch Serverless — Amazon's managed, serverless search and analytics service (derived from Elasticsearch). The target search backend for Portal Search. → AWS docs
MySQL Full Text Search — MySQL's built-in text search capability. The legacy search mechanism being replaced. → MySQL FTS docs
Analyzer (OpenSearch) — A pipeline of character filters, tokenizers, and token filters that determines how text is broken down and indexed for search. "Analyzer tuning" is referenced as a key configuration challenge.
Field Mapping — The OpenSearch schema definition that determines how each field in a document is indexed and stored. → OpenSearch mappings
Containers & Orchestration
Docker — Container platform for packaging applications and their dependencies. → docker.com
Dockerfile — A text file containing instructions to build a Docker container image.
Kubernetes (K8s) — Container orchestration platform for deploying, scaling, and managing containerized applications. → kubernetes.io
kind (Kubernetes in Docker) — A tool for running local Kubernetes clusters using Docker containers. Used to prototype before deploying to EKS. → kind.sigs.k8s.io
k9s — A terminal-based UI for monitoring and managing Kubernetes clusters in real time. → k9scli.io
Helm — A package manager for Kubernetes that uses templated manifests ("charts") to define deployable applications. → helm.sh
Kubernetes Manifests — YAML files that declare desired state for Kubernetes resources (pods, services, deployments, etc.).
AWS Services & Infrastructure
AWS CloudFormation — Infrastructure-as-code service for provisioning AWS resources via templates. → AWS docs
AWS SNS (Simple Notification Service) — Pub/sub messaging service for event-driven architectures. → AWS docs
AWS SQS (Simple Queue Service) — Message queuing service for decoupling distributed systems. → AWS docs
AWS ECS (Elastic Container Service) — Container orchestration service. Mentioned in the context of the Synapse MCP server deployment. → AWS docs
AWS EKS (Elastic Kubernetes Service) — Amazon's managed Kubernetes service. The production deployment target. → AWS EKS docs
AWS WAF (Web Application Firewall) — Firewall service that filters HTTP traffic. A WAF rule was identified as blocking OAuth's
redirect_uriparameter. → AWS docsElastiCache Serverless — Amazon's managed, serverless in-memory caching service. Mentioned in the context of Redis CROSSSLOT errors. → AWS docs
Networking, Auth & Caching
OAuth — An open authorization framework for token-based access delegation. Used by the Synapse MCP server. → oauth.net
Redis — In-memory data store used for caching and session storage. Referenced in the ElastiCache CROSSSLOT debugging scenario. → redis.io
CROSSSLOT error (Redis) — An error raised when a Redis Cluster command operates on keys that hash to different slots. Encountered after migrating to ElastiCache Serverless. → Redis Cluster spec
VPN (Virtual Private Network) — Sage VPN was used to restrict access to the prototype deployment.
DNS (Domain Name System) — Mentioned in the context of migrating the MCP server's domain configuration.
403 Error — HTTP status code indicating a request was understood but forbidden. The WAF rule produced this error during OAuth flow.
Development & CI/CD
GitHub — Source code hosting and collaboration platform. → github.com
GitHub Actions — GitHub's CI/CD platform for automating build, test, and deployment workflows. → docs.github.com/actions
PR (Pull Request) — A GitHub mechanism for proposing and reviewing code changes before merging.
Portal Search Architecture Terms
SearchIndex entity — A Synapse entity type introduced by Portal Search that represents a search index and its lifecycle (creation, population, querying, deletion).
SearchConfiguration — A resource defining how a search index is configured, including analyzer settings and field mappings.
TextAnalyzer — A configuration resource for defining how text fields are analyzed during indexing and search.
ColumnAnalyzerOverride — A configuration resource that lets specific columns override the default text analyzer.
OpenSearch Manager — A component responsible for managing the lifecycle of OpenSearch indexes (creation, updates, deletion).
Lifecycle Workers — Async workers that handle entity state transitions (e.g., building an index, reindexing after schema changes).
Query Workers — Async workers that execute search queries against OpenSearch and return results through the Synapse API.
Concepts & Patterns
MCP (Model Context Protocol) — An open protocol that lets AI tools connect to external services (Jira, GitHub, Gmail, etc.) through standardized server interfaces. → modelcontextprotocol.io
Context Window — The amount of text (measured in tokens) an AI model can process in a single session. Opus 4.6's 1M-token window is cited as key to holding cross-system context.
Correction Loop — The article's core workflow pattern: generate output with AI, identify errors through human review, fix them quickly, and encode lessons learned so future output improves.
CLAUDE.md Network — The distributed set of CLAUDE.md files placed throughout a project's directory tree, each encoding conventions and failure modes specific to that module or layer.